


2021-03-26: celda número 4
De energía, jóvenes, mujeres, éxodos e ideas

246 personas acabáis de recibir en vuestro correo electrónico una nueva edición de FILAS Y COLUMNAS, de las que 48 la estáis recibiendo por primera vez —muchas gracias por vuestro interés—. Si lo que vas a leer a continuación te parece interesante, reenvía el email a otras personas a las que le apasione la estadística y el análisis de datos o compártelo en tus redes sociales. Y si todavía no te has suscrito, puedes hacerlo en el siguiente botón.
Ayer publiqué el siguiente tweet como comentario a uno que había escrito el ministro José Luis Escrivá:


Tras escribirlo, me surgieron algunas preguntas: ¿Qué es un dato? ¿Cómo se mide el número de datos de un archivo? ¿Hay alguna métrica mejor que el ‘número de datos’ para medir el tamaño de una hoja de cálculo o una base de datos?
Todo depende del formato. En un archivo ‘tidy’ de datos es fácil saberlo: número de filas por número de columnas. En formatos más enrevesados, con celdas combinadas, celdas vacías y otras incoherencias de estándares, calcular esta métrica se convierte en una compleja operación de álgebra. Pero existe una regla general que nunca falla para saber si un archivo tiene muchos o pocos datos: el tamaño del archivo. Cuanto mayor pese un archivo, más datos tiene, aunque también influyen otros condicionantes, especialmente el uso o no de códigos alfanuméricos asignados a cada variable en vez del uso de sus nombres completos. Así, los tres archivos publicados por el departamento de José Luis Escrivá pesan 622 KB; la primera estadística que reseño en este boletín, 4.706 KB (4,59 MB); los microdatos del padrón nacional a 1 de enero de 2020, 1.065.790 KB (1,01 GB), y los datos completos de las personas vacunadas de COVID-19 en Brasil, 7,7 GB.
Si algo nos enseñaron los programas de descargas masivas —los Napster, eMule, Ares, Torrent y tantos otros— es a fijarnos en el tamaño del archivo como un indicio de su calidad/volumen. Lo mismo debemos hacer ahora con los archivos de datos.
Empieza, ahora sí, la cuarta celda de FILAS Y COLUMNAS.
La mayor dificultad —que sorprendentemente se ha ido repitiendo— es la falta de estándares de datos. (…) La falta de estándares nos ha obligado a hacer a nosotros ese trabajo de investigación (Sara Bertrán de Lis, científica de datos en la Universidad Johns Hopkins)


Estadísticas energéticas. Eurostat ha actualizado recientemente las estadísticas energéticas de los 27 países europeos con los datos de 2019. Toda la información desde 1990 está disponible en un archivo Excel —descargable en este enlace— estructurado en hojas para cada país. La base de datos muestra cientos de indicadores sobre el balance energético, la producción eléctrica, importaciones y exportaciones o emisiones de dióxido de carbono.


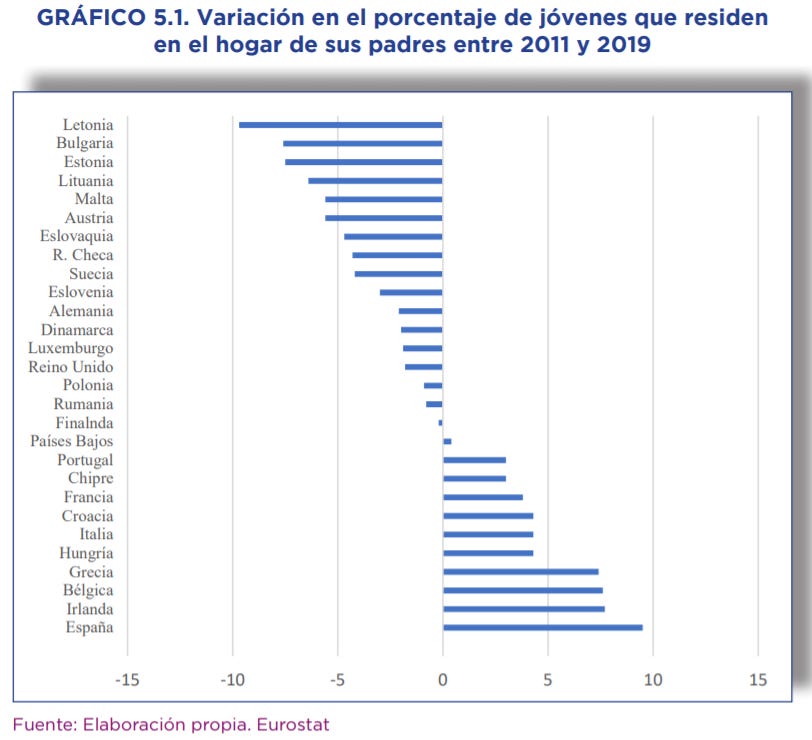
Informe de la juventud. El Instituto de la Juventud (INJUVE) ha publicado el ‘Informe Juventud en España 2020’ —resumen ejecutivo y documento completo de 464 páginas— en el que se analiza las principales características de la población española de entre 15 y 29 años. Gran parte de la información analizada procede de una encuesta de más de 100 preguntas realizada a más de 5.200 jóvenes —la metodología y el cuestionario figuran como anexo del informe completo—.
De entre los muchos gráficos del documento, uno de los que más me ha llamado la atención es el que muestro a continuación sobre la variación por países europeos del porcentaje de jóvenes que vive en casa de sus padres entre 2011 y 2019, con datos de Eurostat. Las conclusiones y posibles causas de este fenómeno vienen automáticamente a la cabeza.
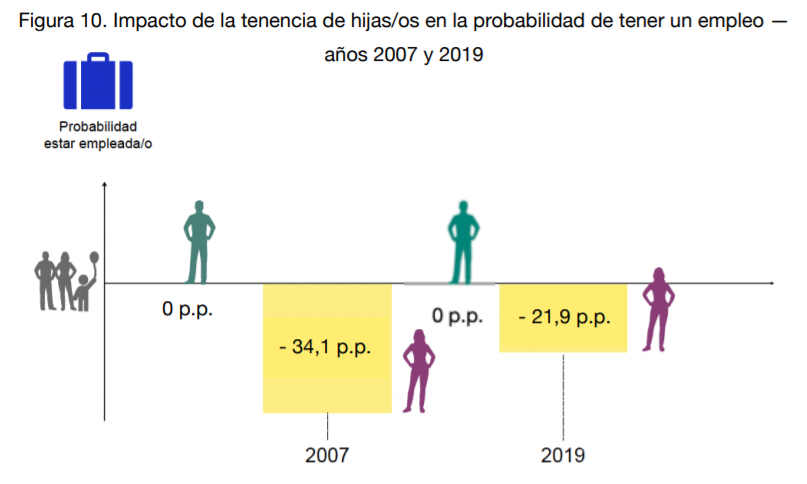
La penalización laboral de ser madre. Odra Quesada, Sara de la Rica y Lucía Gorjón son las autoras de Mujer y madre: la doble penalización laboral, un informe de la Fundación ISEAK en el que se analiza “la situación laboral de mujeres y hombres en tres etapas de sus vidas: cuando viven solas/os, cuando viven con sus parejas pero no tienen hijas/os y cuando, además de vivir con sus parejas, son madres y padres”. Las autoras explican así el principal resultado de su investigación:
Si bien ya existe una brecha de género en materia laboral que es previa a la vida en pareja, ésta se intensifica al vivir en pareja, incluso sin hijas/os, y se agudiza aún más con la llegada de hijas/os
La otra conclusión más importante del informe es la que se muestra en la siguiente infografía y que las investigadoras resumen de la siguiente forma:
Si se compara la situación actual con la de 2007, la brecha en participación laboral ha descendido, pero la brecha en horas trabajadas, por el contrario, ha aumentado
Éxodo interurbano. Tras un primer estudio sobre la Descapitalización educativa y segunda oleada de despoblación publicado en julio de 2019, Miguel González-Leonardo y Antonio López-Gay, del Centre d’Estudis Demogràfics (CED), vuelven a incidir en “la segunda ola de despoblación” que ha afectado a España en la última década. En su nueva investigación, los autores se centran en las migraciones entre capitales de provincias de los jóvenes españoles de 25 a 39 años, observando que desde 2008 Madrid y, en menor medida, Cataluña, han atraído a los jóvenes universitarios de otras capitales de provincia, descapitalizando al resto de provincias españolas.


Algunas de estas conclusiones ya las apuntábamos en la serie de reportajes sobre El éxodo urbano de España: la nueva despoblación del siglo XXI que publicamos en El Confidencial en septiembre de 2019. Habrá que ver si esta tendencia cambia —y se mantiene en el tiempo— a raíz de la pandemia del COVID-19, como apuntan los primeros datos provisionales.
Bonus track internacional. Los investigadores Andrew Gelman y Aki Vehtari han elaborado un paper en el que exponen las que, a su juicio, han sido las ideas estadísticas más importantes de los últimos 50 años. Estos son los ocho avances a los que hacen referencia —las traducciones literales son mías con la ayuda de Google—:
Inferencia contrafactual causal
Bootstrapping e inferencia basada en simulaciones
Regularización y modelos parametrizados
Modelos multinivel
Algoritmos genéricos de cálculo
Análisis adaptativo de decisiones
Inferencia robusta
Análisis exploratorio de datos