


2022-12-09: celda número 41
De contratación pública, corrupción, presión asistencial, censo y escalera social

Soy Jesús Escudero, y si estás recibiendo este email es que alguien —espero que tú— se ha suscrito con tu correo electrónico a FILAS Y COLUMNAS, la newsletter sobre producción estadística y análisis de datos en España —aquí puedes leer el último artículo y la anterior celda—. Si lo que vas a leer te parece interesante, reenvía el email o compártelo en tus redes sociales. Y si todavía no te has suscrito, puedes hacerlo en el siguiente botón.
¿A quién no le ha ocurrido que, tras obtener una base de datos, la abras y no entiendas la metodología empleada, los nombres de las variables o la asignación de determinados valores, especialmente los que representan los datos nulos o vacíos? Para solventar estos y otros problemas se antoja imprescindible la existencia de un diccionario de datos o diseño de registro que acompañe y complemente el dataset.
La consultora en data management Crystal Lewis ha publicado en su blog un par de tutoriales sobre cómo construir y utilizar un diccionario de datos. En el primer artículo, titulado Using a data dictionary as your roadmap to quality data, Lewis enfatiza en la importancia de los diseños de registros incluso antes de la recopilación de los datos:
While a data dictionary, sometimes also called a codebook or variable information log, is often used as a tool to help you and others interpret your data at the end of your project, it is actually even more powerful if created before you ever collect a single piece of data, serving as a roadmap as you design your data collection tools and clean your data, in order to ultimately get to where you want to go.
Además, ofrece un ejemplo sobre la estructura que debería tener un diccionario de datos —en formato tabular, ya sea en Excel o csv, como no podía ser de otra forma—.
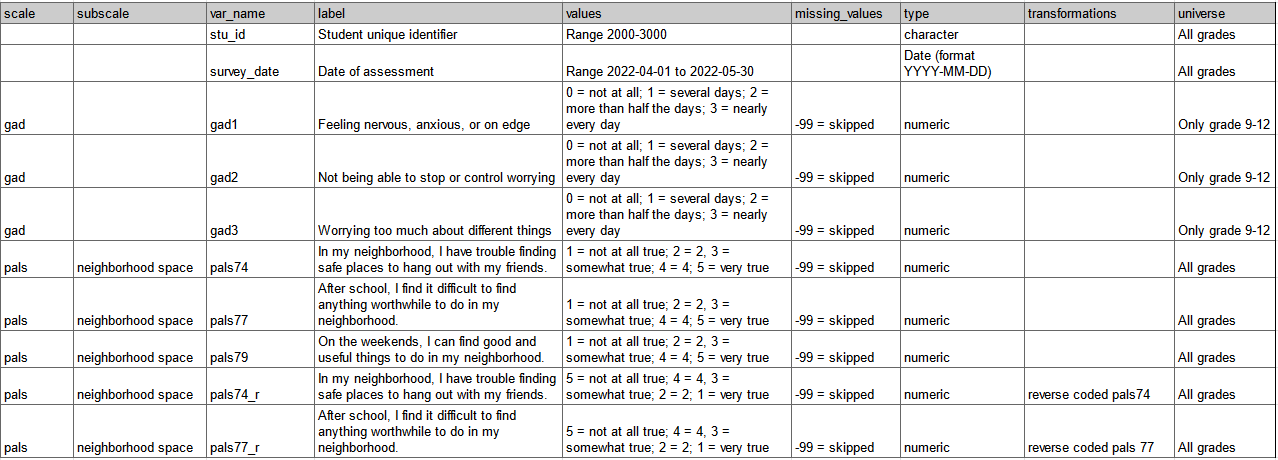
El segundo artículo, Four simple ways to integrate your data dictionary into your data cleaning process, tiene un componente más práctico y se centra en cómo vincular el diseño de registro al dataset durante la limpieza de los datos mediante scripts en R.
Por si fuera poco, Crystal Lewis ha producido un recurso más avanzado sobre Data Management in Large-Scale Education Research, que actualmente está transformando en un libro aún más amplio. Porque como afirma en la introducción de su libro:
Research data management is becoming more complicated. We are collecting more data, in sometimes very novel ways, and using more complex technologies, all while increasing the visibility of our work with the push for data sharing and open science practices. Ad hoc data management practices may have worked for us in the past, but now others need to understand our processes as well, requiring researchers to be more thoughtful in planning their data management routines.
Empieza, ahora sí, la cuadragésima primera celda de FILAS Y COLUMNAS.
Data will tend to offer us solutions based on what we decided was important enough to count and measure in the first place
Georgina Sturge, From migration to railways, how bad data infiltrated British politics, The Guardian, 2022-11-07
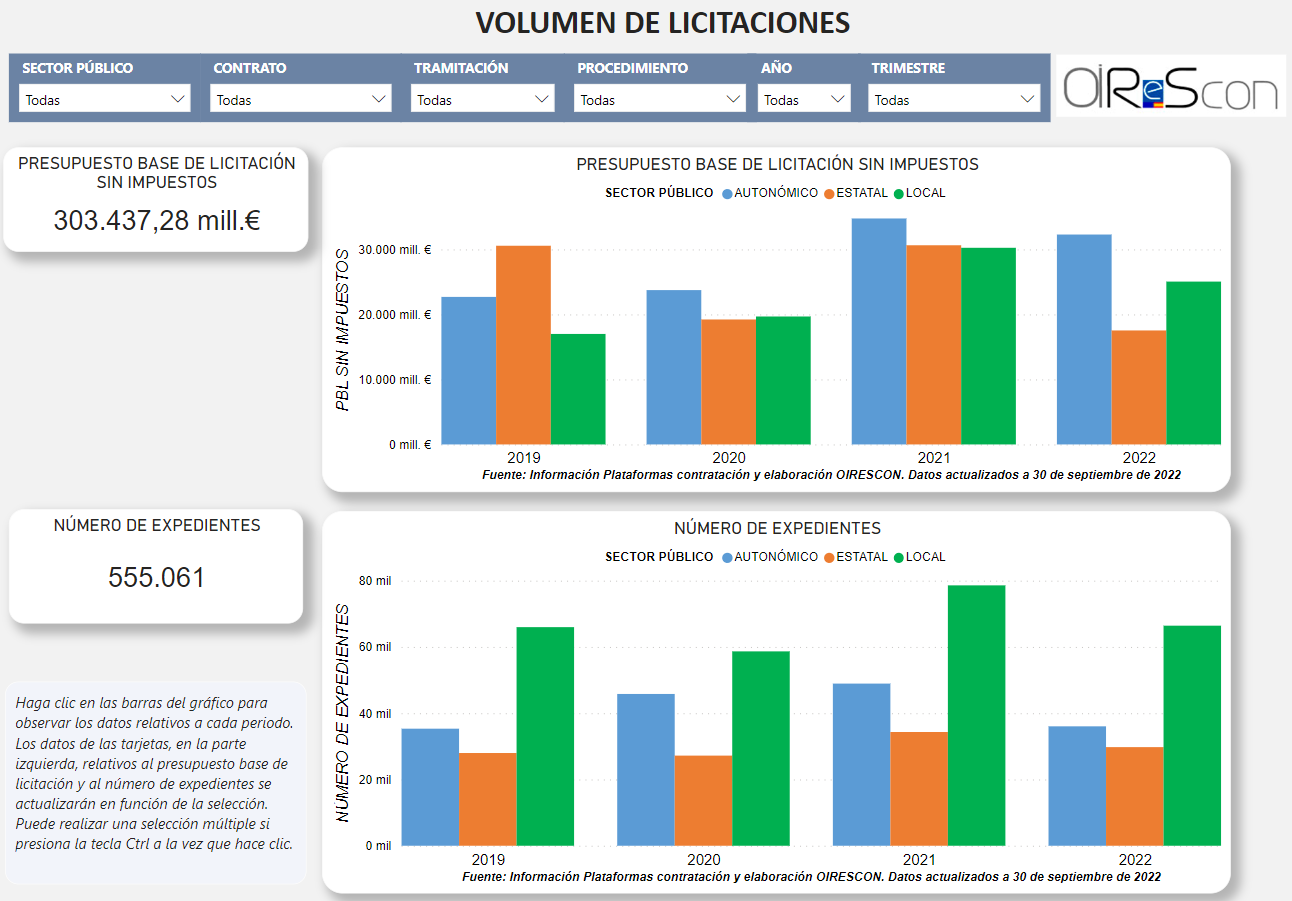
Visor de cifras de la contratación pública. La Oficina Independiente de Regulación y Supervisión de la Contratación (OIReScon) ha desarrollado el Visor de cifras de la contratación pública, “una herramienta que proporciona visualizaciones interactivas de la información personalizada que se seleccione sobre las licitaciones y adjudicaciones públicas, mediante la utilización de diversos filtros”. La información se actualiza trimestralmente a partir de los datos abiertos de la Plataforma de Contratación del Sector Público, incluyendo por tanto la inmensa mayoría de las licitaciones estatales, autonómicas y locales. El visor dispone de nueve páginas en las que se muestra información sobre el número e importe de licitaciones y adjudicaciones, los contratos con licitador único, el número de ofertas por contrato y la reducción económica obtenida en el precio de adjudicación. [visto a Gobierto]
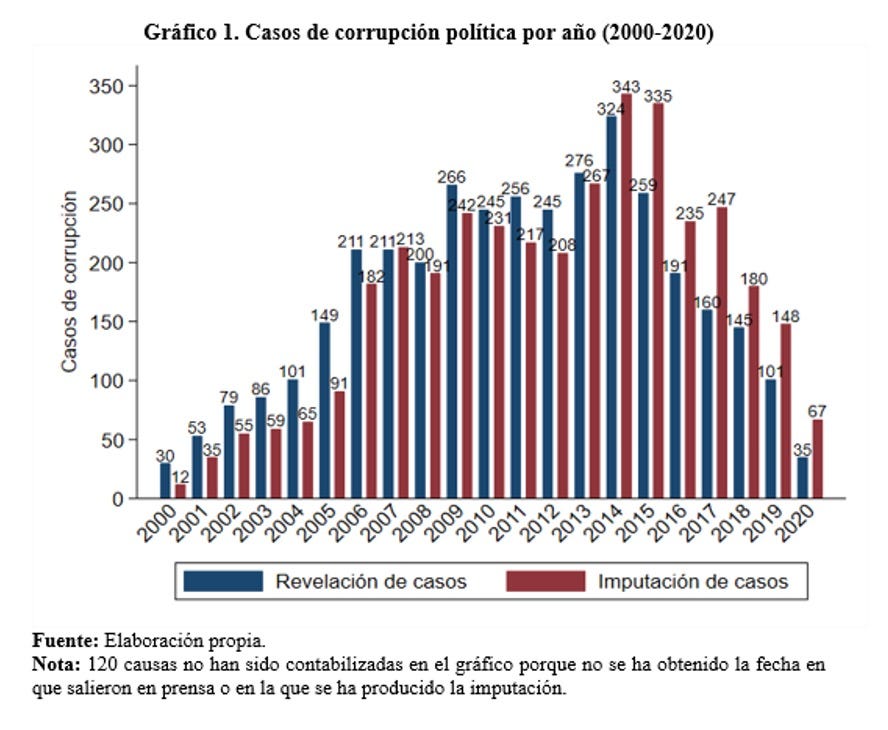
Corrupción política en España. Cuantificar la corrupción política es una tarea complicada, especialmente por la dificultad a la hora de establecer una definición clara y unívoca de lo que significa ‘corrupción política’. José Abreu, doctorando de la Universidad de Las Palmas de Gran Canaria (ULPGC), ha establecido una metodología de trabajo propia con el fin de recopilar “información sobre los casos de corrupción política en España (incluyendo piezas separadas) desvelados en el período 2000-2020, empleando para ello dos hemerotecas digitales: MyNews y Factiva”. Abreu y Juan Luis Jiménez, investigador del Departamento de Análisis Económico Aplicado de la ULPGC, han publicado los primeros resultados del análisis de esta base de datos compuesta por más de 3.700 casos de corrupción política en dos artículos en Nada es Gratis: el primero sobre los datos generales y la distribución territorial y el segundo centrado en el nivel municipal, los partidos políticos y el estado de los casos. [visto a Juan Luis Jiménez]
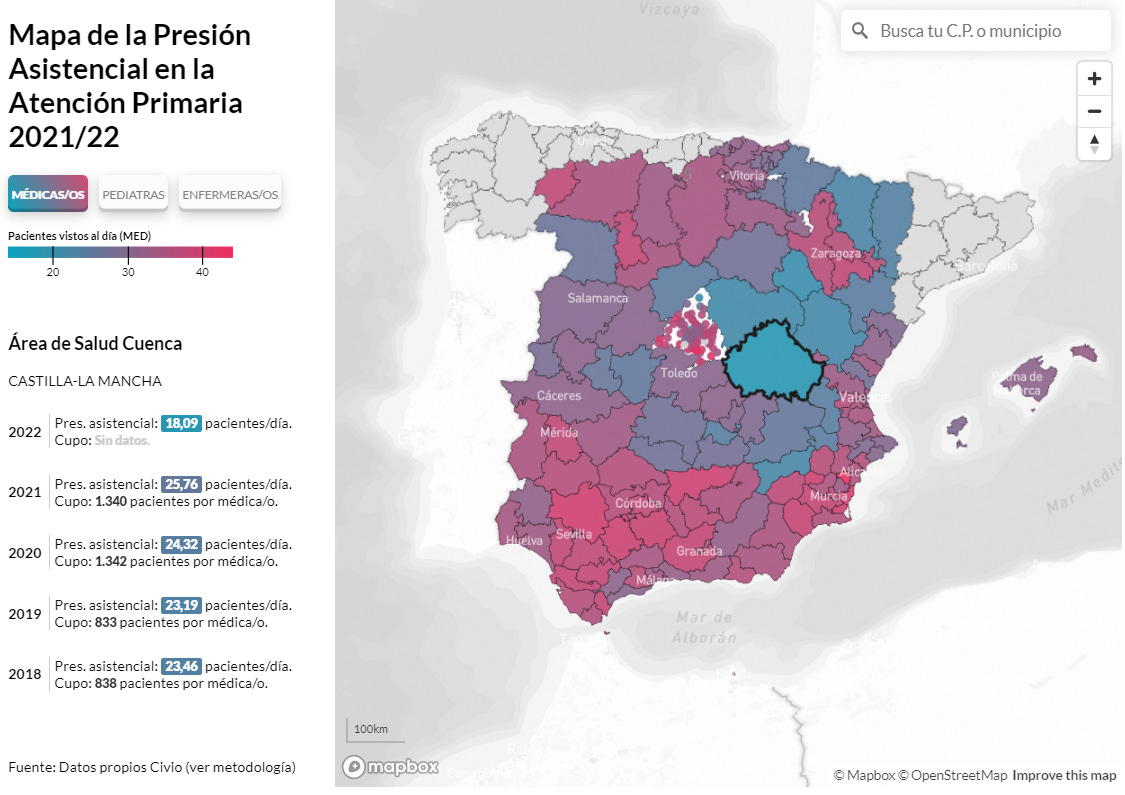
Presión asistencial en atención primaria. Ángela Bernardo, María Álvarez del Vayo, Carmen Torrecillas y David Cabo han trabajado durante meses para recopilar, analizar y difundir datos autonómicos sobre la presión asistencial en atención primaria —media de pacientes vistos al día por médicos de familia y pediatras—. Además de la investigación titulada La excesiva carga de trabajo ahoga a la atención primaria, en donde advierten de que “la realidad es todavía peor que la que dibujan las cifras oficiales de los servicios de salud” por diferentes trucos empleados en el cálculo de las medias, el equipo de Civio ha puesto a disposición de los ciudadanos la información recopilada, tanto en un buscador interactivo como en un repositorio de datos abiertos.
Censo 2021. El Instituto Nacional de Estadística (INE) ha publicado los primeros resultados del censo 2021, la mayor operación estadística de un país y que este año estrena “un nuevo modelo basado en registros administrativos, que proporcionará información censal cada año a partir de 2022”, según la nota de prensa informativa. Los primeros datos ofrecen información sobre la población residente en España a 1 de enero de 2021 y sus características, tales como nacionalidad, lugar de nacimiento, edad media o nivel de estudios. El INE ofrece la posibilidad de consultar esta información en un visor de mapas. Además, algunos medios ya se han hecho eco de algunas de estos resultados:
¿Tu vecino trabaja o está en el paro?: el mapa de la ocupación, calle a calle, El Confidencial, 2022-11-30
España prefiere la costa: así ha cambiado la población de cada provincia desde 1900, eldiario.es, 2022-11-30
La España envejecida: la mitad de los municipios tienen una media de más de 50 años, ABC, 2022-11-30
España gana medio millón de habitantes en una década, pero siete de cada 10 municipios pierden población, El País, 2022-11-30
Llegar a los 100 años y contarlo, El País, 2022-12-04
Bonus track internacional. Un artículo visual de opinión del New York Times recoge los resultados de una investigación de los economistas Ran Abramitzky y Leah Boustan plasmada en el libro Streets of Gold sobre el ascenso en la escalera social de los inmigrantes de segunda generación en Estados Unidos. Interconectando datos del censo con el objetivo de crear “el primer conjunto de datos realmente masivos sobre inmigración”, los investigadores concluyen que los hijos de inmigrantes tienen casi el doble de probabilidades de acabar en el quintil más rico que los hijos de los estadounidenses. Entre las razones que aportan, destacan que los inmigrantes suelen establecerse en territorios con un aumento del empleo y la actividad económica, mientras que los nativos estadounidenses son más reacios a moverse de su entorno.