


2021-04-09: celda número 5
De cuidados infantiles, internet, precariedad, empleadas del hogar y Python

248 personas acabáis de recibir en vuestro correo electrónico una nueva edición de FILAS Y COLUMNAS, de las que tres la estáis recibiendo por primera vez —muchas gracias por vuestro interés—. Si lo que vas a leer a continuación te parece interesante, reenvía el email a otras personas a las que le apasione la estadística y el análisis de datos o compártelo en tus redes sociales. Y si todavía no te has suscrito, puedes hacerlo en el siguiente botón.
Se va a cumplir un mes desde que dejé de trabajar en la Dirección General de Estadística de la Comunidad de Madrid —en la celda número 3 explicaba lo que vi dentro de la Administración en materia de datos y estadística—. Pasado este mes sabático que me ha venido muy bien para desconectar (y arreglar los papeles del paro con los sistemas del SEPE caídos 🤯), el cuerpo y la mente ya me están pidiendo hacer algo de provecho. Así que me voy a lanzar a publicar análisis explicativos en FILAS Y COLUMNAS. De momento, será un post semanal que enviaré los lunes por la mañana. El primero se publicará el lunes 12 de abril.
Esta idea me venía rondando desde hace tiempo, pero por cuestiones laborales y de tiempo no había dado el paso y la tenía en la recámara como opción de futuro. Ahora se dan las condiciones para materializarla. Esto es lo que me propongo hacer:
Tratar realidades sociales más allá de la actualidad diaria. Existen muchas estadísticas y datos públicos que apenas se explotan porque no encajan en la agenda política y mediática, pero que evidencian cambios sociales de gran calado. Serán estos ámbitos hacia donde vaya tirando.
Plantear los análisis como respuestas a hipótesis y preguntas. Las publicaciones de los lunes abordarán cuestiones muy concretas sobre una determinada realidad social a partir de preguntas que me vaya planteando.
Análisis explicativos, no exploratorios. Datawrapper explica muy bien en este articulo la diferencia entre los análisis exploratorios (exploratory) y explicativos (explanatory) de datos. El primer apartado de esta celda de FILAS Y COLUMNAS aborda algunos aspectos del boom de los paneles exploratorios de datos.
Publicar el código y los datasets en GitHub. Otro de mis objetivos personales con estos análisis explicativos es soltarme más con R y GitHub —no hay mejor forma de aprender a utilizar una herramienta que a base de proyectos y del ‘prueba y error’—. Intentaré hacer toda la producción estadística de los artículos en R y publicar en mi GitHub personal tanto el código como los ‘tidy datasets’.
A ver lo que va saliendo.
Empieza, ahora sí, la quinta celda de FILAS Y COLUMNAS.
Sobre los paneles / cuadros de mando / dashboards





Cuidados infantiles. Eurostat acaba de publicar los resultados de una encuesta sobre cómo las familias europeas cuidaban a los hijos menores de tres años en 2019. Aunque se suele hablar de la dependencia de las familias españolas de los abuelos a la hora de cuidar a sus hijos, los resultados de la encuesta muestran un escenario totalmente diferente.
España es el cuarto país europeo —tras Dinamarca, Países Bajos y Luxemburgo— donde más bebés acuden a una escuela infantil al menos una hora a la semana (57,4%). En cambio, apenas el 10% de los niños y niñas de menos de tres años son cuidados por sus abuelos, otros familiares o niñeras durante el mismo tiempo. El siguiente mapa refleja una clara división a la hora de cuidar a los hijos: Europa Occidental y Escandinavia se decantan por las escuelas infantiles, mientras que en la Europa Oriental a partir de Italia y Alemania los cuidados infantiles son responsabilidad exclusiva de los padres (salvo Eslovenia).

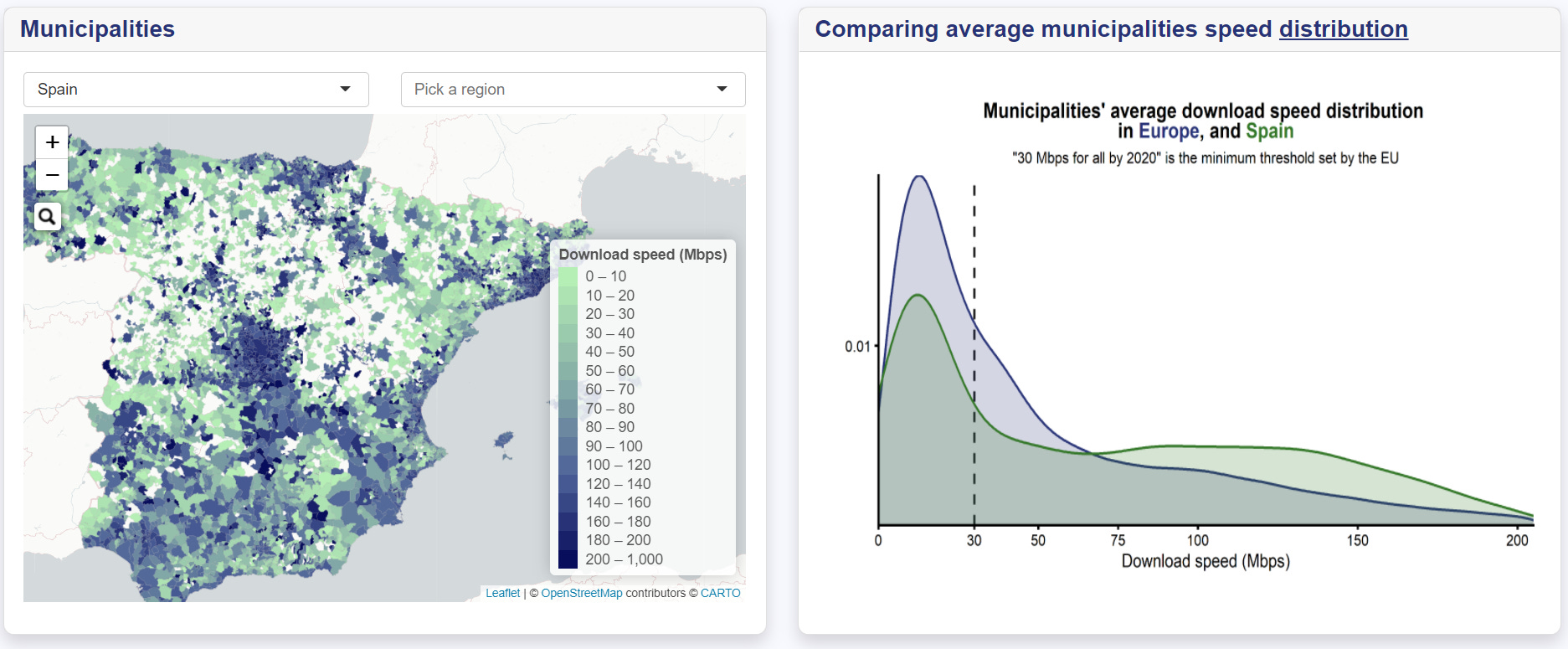
Velocidad de internet. European Data Journalism Network ha lanzado una herramienta interactiva donde muestran a través de mapas e histogramas la velocidad media de internet en municipios, provincias, regiones y países europeos. Los datos proceden de un análisis realizado con la herramienta Speedtest de Ookla durante el cuarto trimestre de 2020, y se pueden descargar en este enlace.
España no sale nada mal en la comparativa al ser uno de los países europeos con las velocidades de internet más elevadas. Eso sí, a medida que entramos en un mayor nivel de detalle territorial, vemos cómo en las áreas más rurales y vacías de Aragón y las dos Castillas la cobertura de internet va desapareciendo. Lo contrario sucede en las áreas con mayor densidad de población de Madrid, Barcelona, Andalucía, Murcia y País Vasco.
Precariedad laboral. Segunda newsletter consecutiva que un informe de la Fundación ISEAK aparece en FILAS Y COLUMNAS. En esta ocasión se trata de un estudio sobre la precariedad laboral, titulado El efecto cicatriz de la precariedad laboral: ¿cómo afecta al futuro de la juventud en España? —informe completo en inglés y policy brief en español—. A partir de los microdatos de la Muestra Continua de Vidas Laborales de la Seguridad Social, las investigadoras analizan las condiciones de base que determinan una mayor probabilidad de caer en la precariedad laboral a medio y largo plazo. Una de las investigadoras, Lucía Gorjón, resume así los principales hallazgos de la investigación:


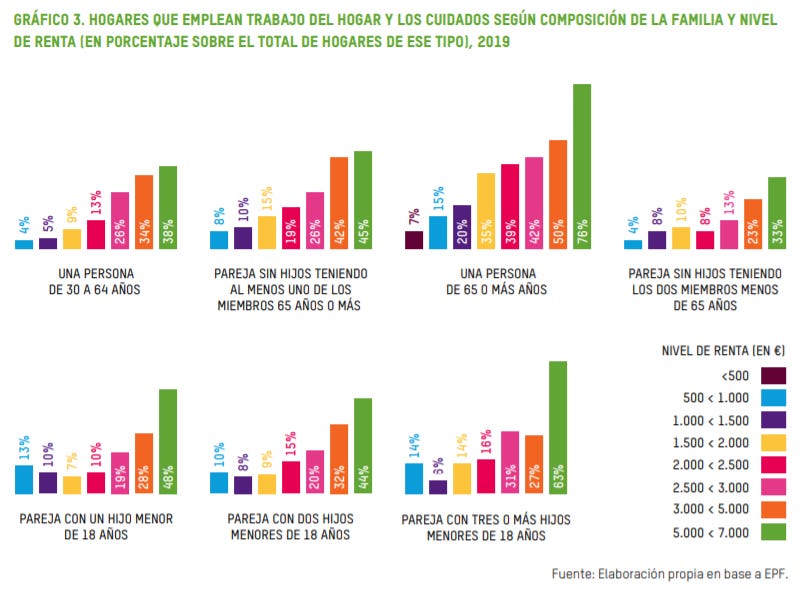
Trabajadoras del hogar. Liliana Marcos Barba es la autora de un estudio publicado por Oxfam Intermon sobre el perfil y las condiciones laborales de las trabajadoras del hogar en España. Titulado Esenciales y sin derechos, el informe combina a lo largo de 80 páginas los gráficos estadísticos explicativos con testimonios en primera persona de las empleadas del hogar y las familias para las que trabajan.
Uno de los gráficos más interesantes es el que ilustra las características de los hogares que emplean trabajo del hogar y los cuidados. Así, los hogares de una persona mayor de 65 años y las familias numerosas son las que emplean un mayor porcentaje de empleadas del hogar. La renta familiar es otro factor que influye a la hora de emplear trabajo del hogar: a mayores ingresos familiares, mayor es la posibilidad de recurrir a una trabajadora del hogar para las tareas domésticas.
Bonus track internacional. investigate.ai es una web dirigida especialmente a periodistas que quieran hacer ciencia de datos con Python. El apartado más interesante es el que recoge reportajes reales y casos de estudio de investigaciones periodísticas en los que el análisis de datos con Python ha jugado un papel fundamental. En total son 26 proyectos de medios como The New York Times, BuzzFeed, ProPublica, Bloomberg o Tampa Bay Times de los que se detalla todo el proceso de producción estadística y periodística, incluido el código utilizado para scrapear, limpiar, depurar y analizar los datos.