


2021-12-03: celda número 20
De anuario, sociedad digital, viviendas en propiedad, ciclocarriles y censos

Soy Jesús Escudero, y si estás recibiendo este email es que alguien —espero que tú— se ha suscrito con tu correo electrónico a FILAS Y COLUMNAS, la newsletter sobre producción estadística y análisis de datos en España —aquí puedes leer el último artículo y la anterior celda—. Si lo que vas a leer te parece interesante, reenvía el email o compártelo en tus redes sociales. Y si todavía no te has suscrito, puedes hacerlo en el siguiente botón.
Durante las pasadas semanas han circulado por Twitter los siguientes memes y viñetas:




El mensaje de ambas viñetas parece claro: en la era de los datos, la estadística representa la sobriedad pero al mismo tiempo la falta de popularidad —por la segunda viñeta, no por Adam Driver—.
Estas dos imágenes se suman a la pregunta que Sarah Friedrich y otros investigadores alemanes se hicieron hace un tiempo y han contestado recientemente: ¿La estadística tiene hueco en la inteligencia artificial? La respuesta es un rotundo sí.
El paper de 24 páginas desgrana todas las ventajas que la estadística puede aportar a la inteligencia artificial, especialmente en cuanto a la validación, representatividad —”la ingenua expectativa de que una suficiente cantidad de datos conduce automáticamente a la representatividad es incorrecta”—, detección de sesgos y estabilidad de los modelos. Pero si de algo sabe la estadística es sobre la calidad del dato:
‘Data is the new oil of the global economy.’ According to, e.g., the New York Times (New York Times 2018) or the Economist (The Economist 2017), this credo echoes incessantly through start-up conferences and founder forums. This metaphor is not only popular but false. First of all, data in this context corresponds to crude oil, which needs further refining before it can be used. In addition, the resource crude oil is limited. ‘For a start, while oil is a finite resource, data is effectively infinitely durable and reusable’ [Bernard Marr in Forbes (2018)]. All the more important is a responsible approach to data preprocessing
Y en este procesamiento de los datos es donde entraría la estadística para garantizar la calidad del dato a partir de las dimensiones de relevancia, precisión, confianza, oportunidad, puntualidad, coherencia, comparabilidad, accesibilidad y claridad, tal y como lo refleja el Sistema Estadístico Europeo en un documento de 2019.
Con todo ello, no es de extrañar que los investigadores concluyan que:
With its specialist knowledge of data evaluation, starting with the precise formulation of the research question and passing through a study design stage on to analysis and interpretation of the results, statistics is a natural partner for other disciplines in teaching, research and practice
Empieza, ahora sí, la vigésima celda de FILAS Y COLUMNAS.
5% de trabajo excitante, 95% de mera introducción de datos

Anuario Estadístico mundial. Naciones Unidas ha publicado su Anuario Estadístico 2021 a la antigua usanza: en un documento de 542 páginas con todo tablas y ningún gráfico —para encontrar los datos descargables en CSV, hay que abrir el árbol de carpetas con las 34 tablas que forman el anuario—. Los 34 indicadores recogen información de todos los países y se agrupan en tres bloques: población y sociedad; economía; y energía, medio ambiente e infraestructuras. Destaco las tablas que recopilan información sobre el porcentaje de mujeres en los parlamentos nacionales, profesionales de la salud o especies en peligro de extinción por países.
Estadísticas en la sociedad digital. El último número de la Revista Índice, editada por el INE y la Universidad Autónoma de Madrid, está dedicado a las Estadísticas en la sociedad digital. A lo largo de siete artículos y dos entrevistas, la publicación aborda los retos de la estadística en esta era del big data y de qué forma la estadística oficial se está adaptando a las nuevas fuentes de datos más granulares, diversas y en tiempo real. Esta mayor granularidad ha llevado a Emanuele Baldacci, Fabio Ricciato y Albrecht Wirthmann, de Eurostat, a acuñar el término nano-data —que podría traducirse al español como nanodatos—, tal y como explican en su artículo A Reflection on The Re(Use) of New Data Sources for Official Statistics:
If ‘micro-data’ refers to the characteristics of an individual, the term ‘nano-data’ was proposed to refer to granular, behavioural data referring to individual events at sub-individual level. Private companies collect nano-data primarily for business purposes (e.g., for delivering services to their customers, or to gain more detailed knowledge about their needs and behaviours) and statistical offices are eager to reuse such data for producing more, better and timelier official statistics
Polarización en la propiedad inmobiliaria. Diederik Boertien y Antonio López-Gay, investigadores del Centre d’Estudis Demogràfics, son los autores del estudio Hogares y propiedad inmobiliaria: estrategias de acumulación y desigualdad en España, 2002-2017 publicado en Perspectives Demogràfiques. A partir de datos de la Encuesta Financiera de Familias del Banco de España, los autores analizan cómo la mayor adquisición de propiedades inmobiliarias por las clases altas tras la crisis económica de 2008 ha provocado un aumento de la desigualdad. Este fenómeno hizo que en 2017 hubiera más hogares con tres o más propiedades inmobiliarias (20%) que familias sin ningún inmueble en propiedad (18%), cuando en 2002 estos porcentajes eran del 9% y el 14%, respectivamente. De ahí que los investigadores alerten de estas
dos tendencias opuestas en relación con el acceso a la propiedad inmobiliaria en España (los que no pueden comprar y los que acumulan más de una) y cómo este fenómeno es clave para entender la desigualdad de riqueza de los hogares en España


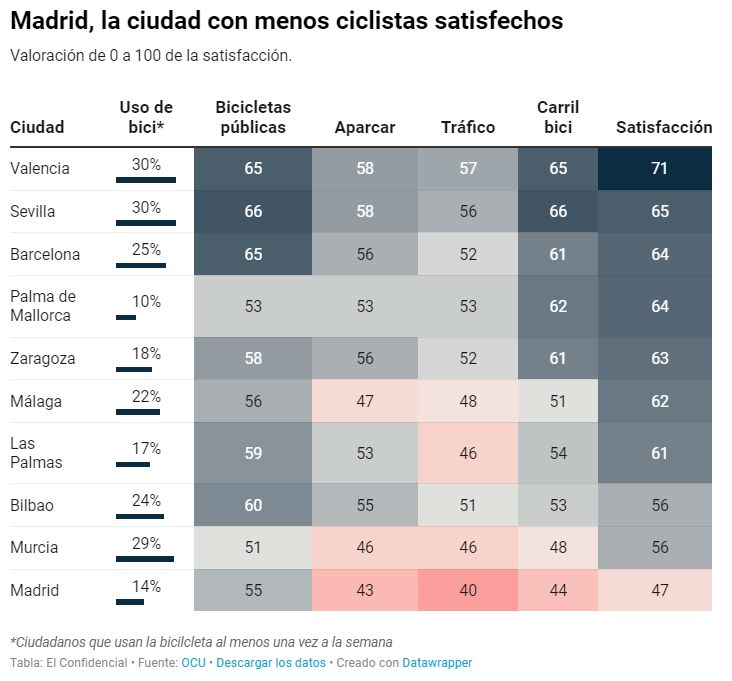
Exceso de velocidad en los ciclocarriles. Pese a la bicicleta y la señal de 30 pintadas en la calzada, ningún vehículo circula a 30 kilómetros por hora por los ciclocarriles de Madrid. Con un radar móvil con forma de pistola, Alfredo Pascual, periodista de El Confidencial, dedicó la mañana de un lunes a medir la velocidad de los turismos, motos y autobuses que circulaban por tres ciclocarriles de Madrid. El resultado: “Prácticamente ninguno de los vehículos medidos circuló a menos de 30 km/h, situándose la horquilla más común entre los 42 y los 55 km/h; esto es, más o menos la misma velocidad que cuando el límite es a 50 km/h”. Más allá del exceso de velocidad en los ciclocarriles, el reportaje aborda las diferencias entre ellos y los carriles bici —separados de la circulación— y cómo Madrid se ha convertido en una de las peores ciudades españolas para moverse con bicicleta, según se refleja en la siguiente tabla.
Bonus track internacional. La inmensa mayoría de los países están llevando a cabo actualmente sus censos decenales. Para abrir boca antes de que se conozcan los primeros resultados, la oficina nacional de estadística británica —ONS por sus siglas en inglés— ha comenzado una serie de publicaciones para comparar la Inglaterra y Gales de 1961 con las de 2011. El primer artículo muestra el número de hogares sin aseo ni bañera, el estado civil de las personas o cuántos ciudadanos eran propietarios de viviendas. La publicación es el resultado de un esfuerzo colaborativo de 2.800 voluntarios que han clasificado 5,5 millones de registros para poder digitalizar el Censo de 1961. El proyecto se ha desarrollado en la plataforma Zooniverse, donde está explicada la metodología y el proceso de investigación de este rescate masivo de datos.